Sometimes we need to have different spaces link together. This calls for a very accurate reconstruction of the locations. Here is my journey on connecting multiple AI generated rooms together.
The first episode of the game starts from your home. The home apartment location consists of multiple rooms that connect together with doorways. In these occasions, you might sometimes clearly see the other room from the other room. This is impossible to achieve using Midjourney in it’s current state.
My hypothesis was to model the rooms in 3D separately first, then align them in the same 3D space and make the doors transparent. This 3D scene could then be used to acquire screenshots with depth information that could be used in ControlNet in Automatic1111 to blend the scenes together.
Prompting
The initial images for the locations were created in Midjourney v4 as per usual. I generated a massive amount of images with slightly different variations. I just wanted a big mass of options to choose from. To see which rooms would fit together.

I generated images for a bunch of different spaces that the player could explore. A kitchen, bathrooms, lobbies, bedrooms and hallways.
I was not expecting Midjourney to do a perfect job. I knew I would need to do a lot of inpainting to add doors and various items to the rooms. I had not yet tested how this would work, but I was pretty optimistic.




I managed to generate a bunch of rooms the I liked and had the elements that I would need in order to get the apartment location done. I just needed to make sure the player could plausibly move from one room to another.
Trying to train an AI + other experiments
As these Midjourney generated images would need to be altered quite a bit, I needed to be able to create a matching style in stable diffusion. The solution is to train a custom stable diffusion model or embedding on the images Midjourney Generated. I tried a couple of different methods for this.
If I found out that getting leasing results was too fickle using AI, I was prepared do the scene blending by hand.
Locally with Automatic1111 and ControlNet
For the local training I first tried to use Automatic1111 to train an embedding. Embeddings are simple vectors that drive the model based on textual inversion from pre-existing images. It is similar to the interrogate feature in Midjourney. I trained the embedding on a few of my Midjourney generated images to see how this would work in copying the Midjourney style.
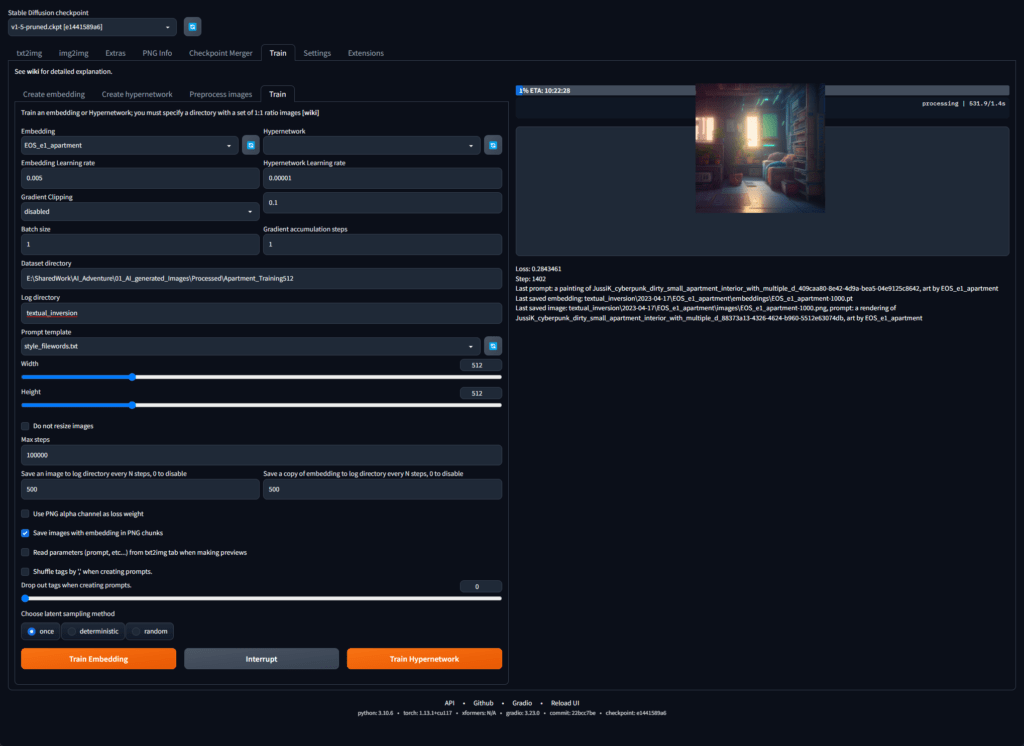
The end results really were not anything spectacular. I tried using ControlNet to drive the generation on top of the embedding, but the results just looked awful.



Trying to get the AI to generate something very specific or to drive a pre-existing, heavily stylised image to a certain direction is very very difficult.
Online based Stable Diffusion (Scenario)
As the embedding were a bust, I decided to try an online tool as well.
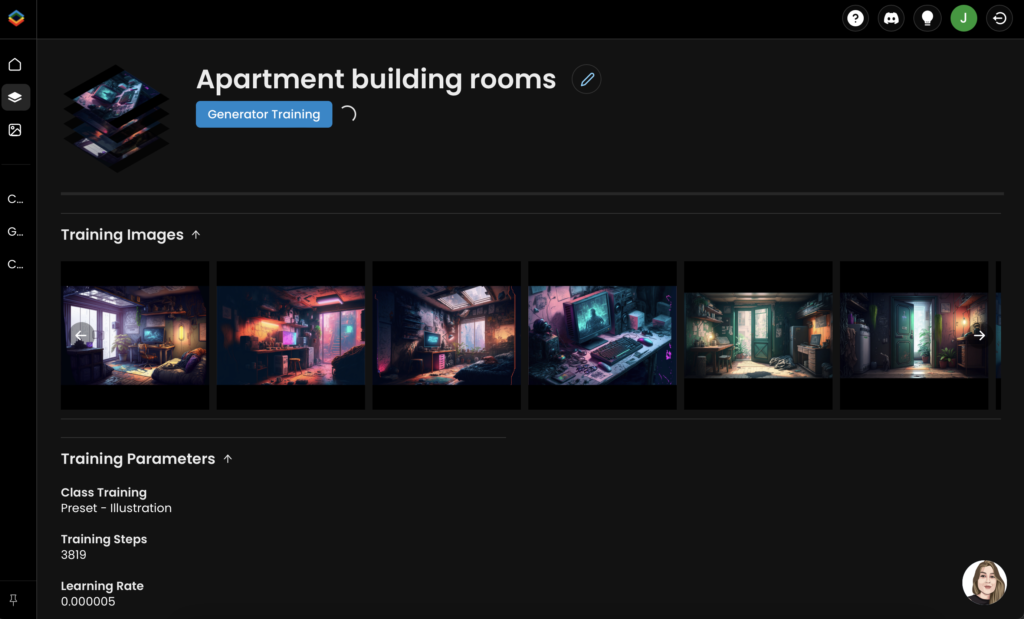
For the online training I used Scenario.com. It is an online user interface built on top of Stable Diffusion. Training a model in this online tool is very easy. I just dragged all of the midjourney generated images into the training page and Scenario automatically cropped everything for me and started the training process.
The results with scenario were a lot better, but far from perfect. The new areas my custom stable diffusion model generated did not a 100% match the image I was expanding on, but these results would be passable in a pinch.

My first experiment was to try to outpaint the room location to get a wider angle on the small room. I really do not like to allow the characters to get too close to the camera. This was just a quick test and the result is far from perfect.
Stable diffusion based tools have always been a little hard for me. They seem to require afar better use of prompting and tinkering to get right. But once you have it set up just the way you like, oh boy is it ever good! One very important aspect of using any Stable Diffusion based tool is negative prompting.I did not use any of it here. I usually tend to just have too little time to spend on tweaking and tinkering.
Using Dall-e 2 image editing
I had previously written off Dall-e as being a tool that produces somewhat boring images. But I decided to give it a go for extending the bedroom location, as I felt it was zoomed in way too close.

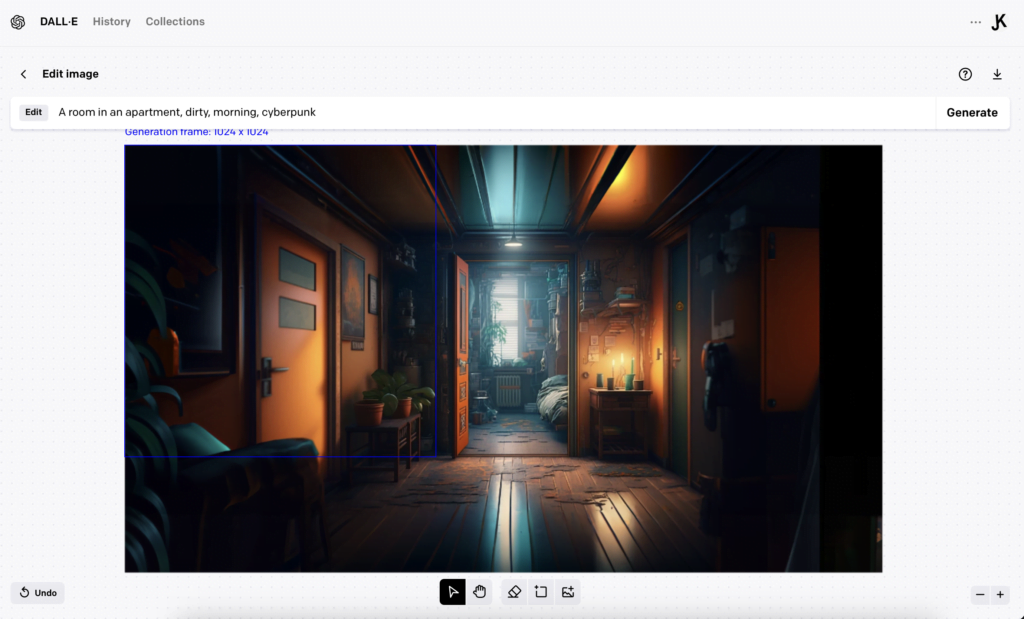
Dall-e’s outpainting proved to be so coherent and effortless. It was simply the easiest solution so far to use out of the box! Who would have known!
But in the world of generative AI, things move so fast and as I was writing this a new challenger entered the arena…
Adobe Photoshop/Firefly Generative AI tools

Around this time, a new beta version of Adobe Photoshop was released. The new feature in this beta was built in image generation and in- / outpainting using Adobe Firefly.

I tried to extend and edit the scene in Photoshop to see how it would work. And it was almost perfect. My favourite thing is that you can extend images without any prompt present. It will just match the image look and feel and give you more of it.
Here is the workflow for the bedroom / lobby scene in photoshop:
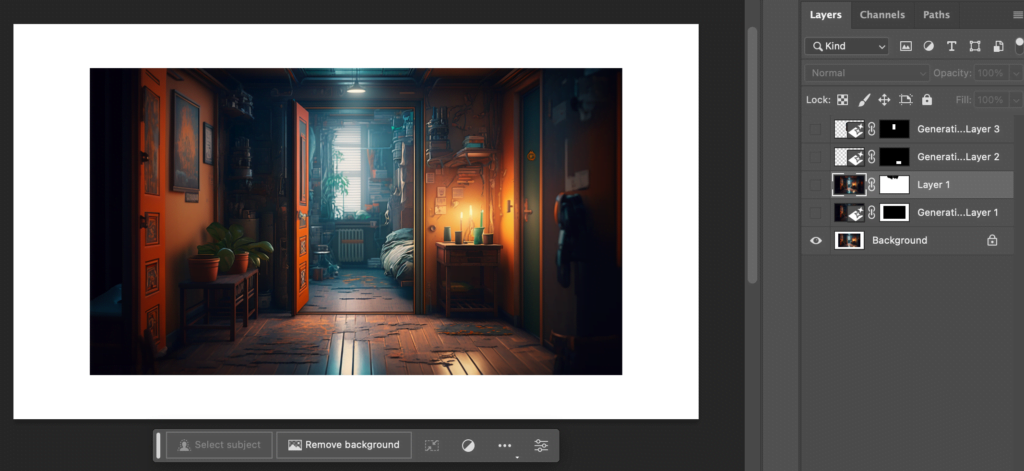



When you factor in the editing tools that Photoshop has out of the box, editing Midjourney creations in photoshop is a breeze! For my use-case, Photoshop simply had the best toolset – for now!
The generated parts of the image are not at par with the midjourney generated imagery, but they are close enough. And the ease of use is unparalleled.
Here is the example video of the workflow of an image editing in Photoshop with the new generative tools:
In this video you can see me first use the generative tools to edit the image and then afterwards match the lighting of the image to the neighbouring room.

These new tools, even though have existed elsewhere for a while, have never been this easy to use as a part of an art creation workflow. As a professional.
I still expect the smaller, specialised AI tools to be more easily accessible for the majority of people.

The ease of editing in Photoshop allows me far greater leeway when selecting the starting image from Midjourney. It does not need to be perfect. I know with confidence that I can do the changes I need very quickly.
In the next part, I will model and combine these scenes together. I have a little bit of a twist in mind for this location!
I have recently begun to split these bigger posts into a couple of parts. How does this feel? is it ok or would you like to have less posts and see the result as 3D captured in game in the first post?





Leave a Reply